新智元报道
编辑:桃子
【新智元导读】强化学习,或许并不能通往AGI终点。Karpathy最新发文提出另一种Scaling范式,像人类一样反思回顾,通过复盘学习取得突破,更多的S形进步曲线等待发现。
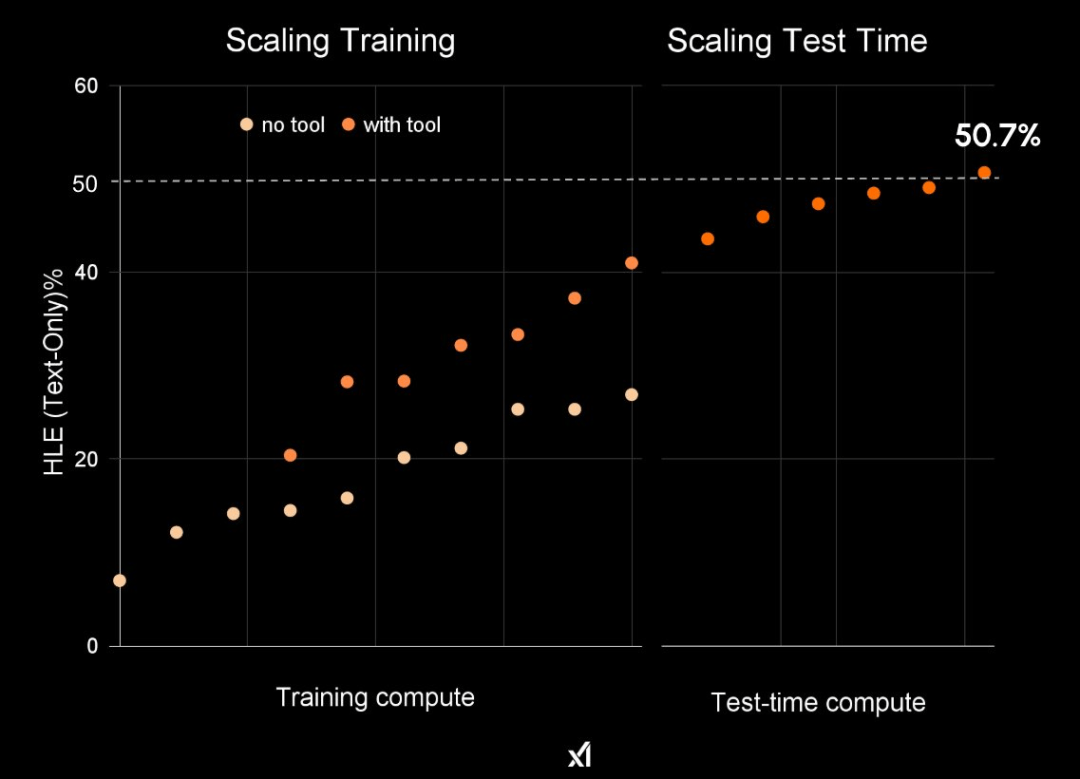
Grok 4能站在大模型之巅,全是Scaling强化学习立了大功。
如今,AI大神Karpathy站出来急泼一盆冷水:
RL只是把最终成败的单一数值回传,效率随任务时长急剧下降。
而且,RL与人类「反思-提炼-再应用」迭代机制存在巨大差异。
RL短期有效
真正突破在于「复盘学习」
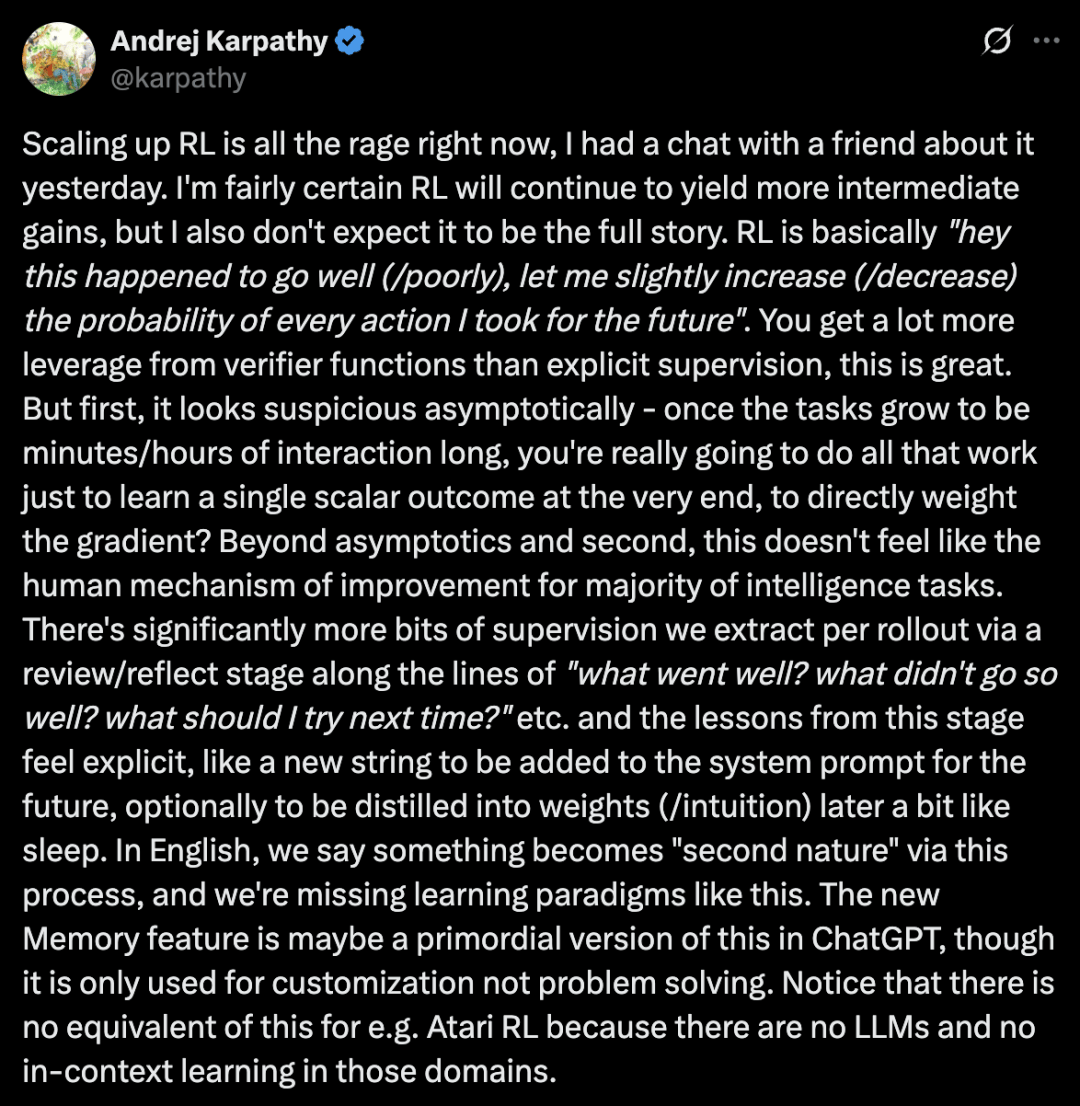
强化学习的本质是,某次行动表现良好(糟糕),就略微提升(降低)未来类似行动的概率。
这种方法通过验证函数,比显示监督取得了更大的杠杆效应,无疑是其强大之处。
然而, 在Karpathy看来,从长远角度来讲,强化学习或许并不是最优策略。
长时程任务,RL局限显现
首先,一旦任务交互时间增加到几分钟乃至几小时,RL就遇到了挑战。
想象一下,一个数小时交互的任务,最终却只得到一个单一的标量奖励,来调整整个过程的梯度。
这样的反馈,能否足以支撑高效学习?

RL机制与人类差异显著
其次,对于大多数智能任务而言,这感觉并不像人类的进步机制。
简言之,RL的机制与人类智能提升方式,存在着显著的差异。
人类会通过一个复盘/反思阶段,从每一次推演中能提取到多得多的监督信息,比如「哪里做得好?哪里不太行?下次该试试什么?」等等。
从这个阶段得到的教训感觉是明确的,就像一个新字符串,可以直接添加到未来的系统提示词里,也可以选择性地在之后被「蒸馏」成权重/直觉,有点像睡眠的作用。
在英语里,我们说通过这个过程,某件事会成为人的「第二天性」,而我们目前正缺少这样的学习范式。
这里,Karpathy提到了ChatGPT「记忆」功能,或许就是这种机制概念的一个雏形,尽管它目前只用于个性化,而非解决问题。
值得注意的是,在Atari游戏这类RL场景中也不存在类似的机制,因为那些领域里没有大语言模型,也没有上下文学习。
算法新设想:回顾-反思范式
为此,Karpathy提出了一个算法框架——
给定一个任务,先跑几次推演,然后把所有推演过程(包括每次的奖励)都塞进一个上下文,再用一个元提示词来复盘/反思哪些地方做得好或不好,从而提炼出一个字符串形式的「教训」,并将其添加到系统提示词中(或者更通用地,更新当前的教训数据库)。
不过,他表示,这里面有很多细节要填充,有很多地方可以调整,具体怎么做并不简单。
举个栗子,大模型计数问题。
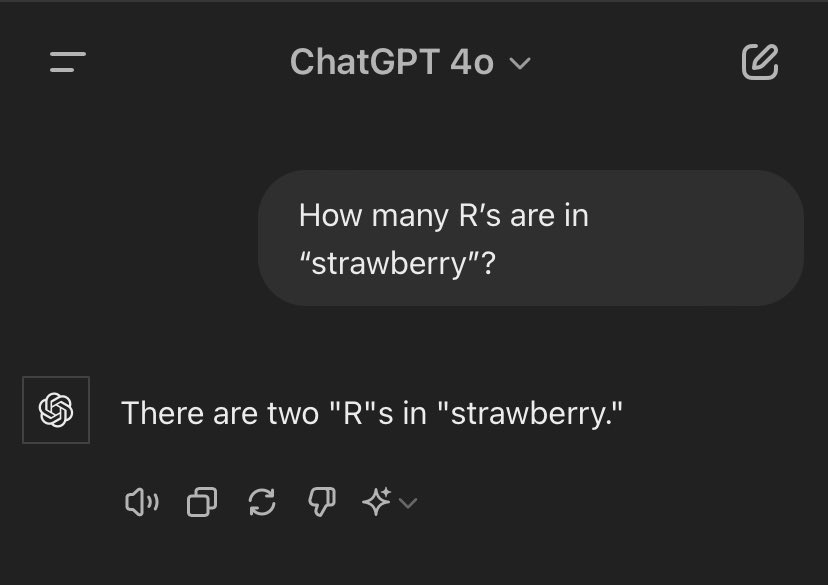
Claude的系统提示词里就加入了一个「快速修复」patch——添加了一段话,大意是:「如果用户让你数字母,你得先用逗号把字母隔开,每隔一个就给一个显式计数器加一,照这样做完任务」。
这段话就是「教训」,它明确地指导模型如何完成计数任务。
但问题在于,这种教训要如何从智能体的实践中自发产生,而不是由工程师硬编码进去?它该如何被泛化?
以及,这些教训如何随着时间推移被蒸馏,从而避免让上下文窗口无限膨胀?
最后,他总结道,RL会带来更多收益,如果应用得当,它的杠杆效应巨大。
并且,深受「惨痛教训」(bitter lesson)理论的启发,RL优于监督微调(SFT)。
但它并不是完整的答案,尤其是随着推演的流程越来越长。
在这之后,还有更多的S型增长曲线等待发现,这些曲线可能专属于大语言模型,在游戏/机器人这类环境中没有先例,而这,正是我觉得激动人心的地方。
OpenAI研究科学家Noam Brown对此深表赞同,「确实,未来仍有许多研究工作有待完成」。
AI初创公司联创Yuchen Jin提出了一个有趣的观点,全新训练范式——课程学习,是一个自监督记忆+检索+反思的反馈循环,无需任何外部奖励信号。

一位网友很有见地称,强化学习实际上是暴力试错的一种方法,并非是明智的策略。

放弃无效RL研究
最近,关于强化学习的讨论,成为了AI圈的一大热点。
除了Karpathy本人下场,上周前OpenAI研究员Kevin Lu发长文称,Transformer只是配角,放弃无效RL研究!

他直言,真正推动AI规模跃迁的技术是互联网,而非Transformer,这也是你应该停止RL研究,转投产品开发的原因。
众所周知数据才是AI最重要的要素,但研究者们却往往选择回避这个领域...
究竟什么才是规模化地做数据?
互联网提供了天然的数据宝库:海量且多样化的数据源、自然形成的学习路径、反映人类真实需求的能力维度,以及可经济高效规模化部署的技术特性——
它成为下一个token预测的完美搭档,构成了AI爆发的原始汤池。
没有Transformer,我们本可以用CNN或状态空间模型达到GPT-4.5的水平。
但自GPT-4之后,基础模型再未出现突破性进展。
专用推理模型在垂直领域表现优异,却远不及2023年3月GPT-4带来的震撼级跨越(距今已两年多...)。
RL确实成就斐然,但Kevin Lu对此深切担忧,研究者会重蹈2015-2020年间RL研究的覆辙——沉迷于无关紧要的学术游戏。
如果说互联网是监督预训练的时代搭档,那么什么才能成为强化学习的「共生体」,催生出GPT-1到GPT-4量级的飞跃?
Kevin Lu认为答案在于:研究-产品协同设计。